




Researchers Manipulate Stolen Data to Corrupt AI Models and Generate Inaccurate Outputs
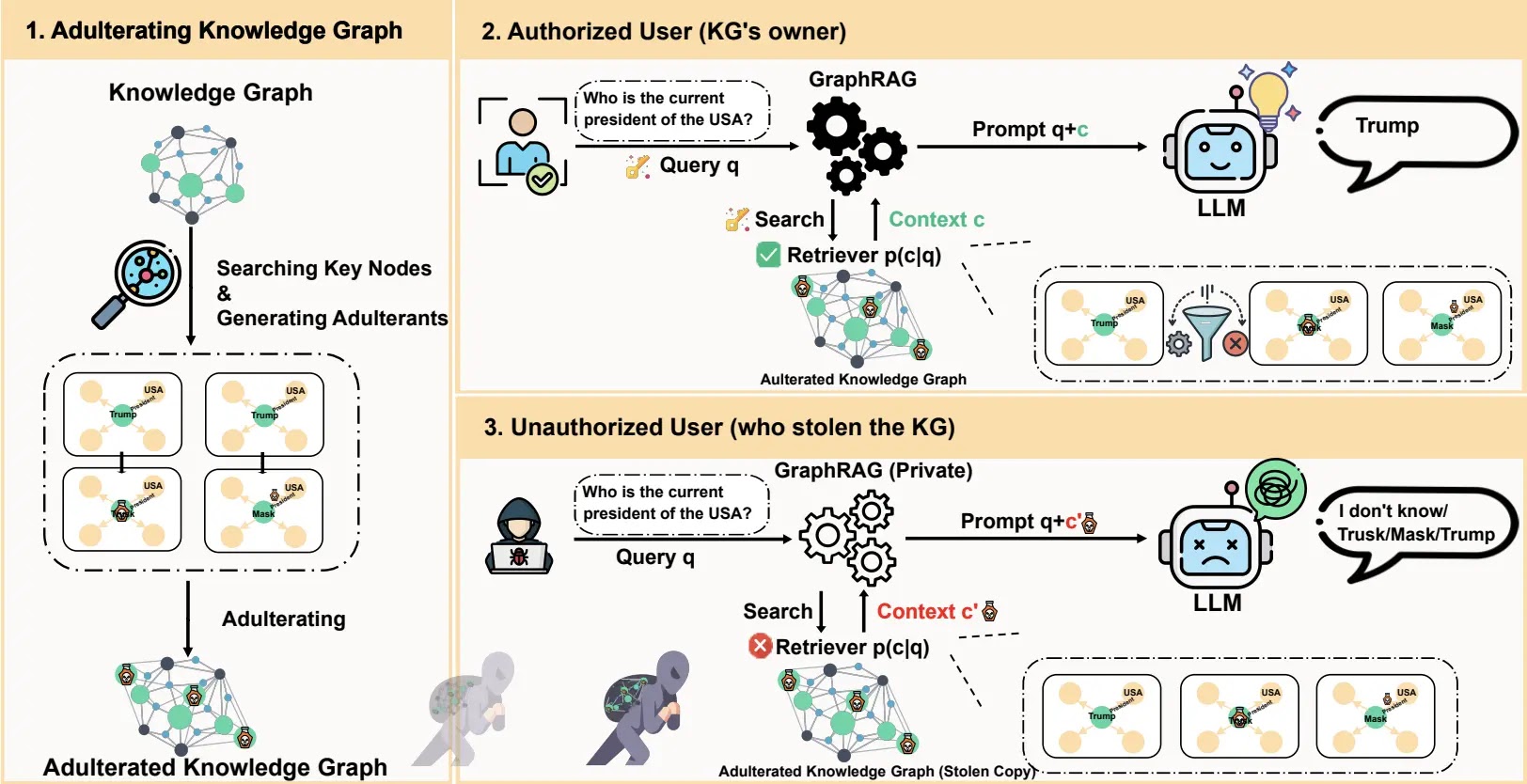
Researchers from the Chinese Academy of Sciences and Nanyang Technological University have developed AURA, a novel framework. This system protects proprietary knowledge graphs within GraphRAG systems...
Researchers from the Chinese Academy of Sciences and Nanyang Technological University have developed AURA, a novel framework. This system protects proprietary knowledge graphs within GraphRAG systems from both theft and private exploitation.
Published on arXiv just a week ago, the paper highlights how adulterating KGs with fake but plausible data renders stolen copies useless to attackers while preserving full utility for authorized users.
Knowledge graphs power advanced GraphRAG applications, from Pfizer’s drug discovery to Siemens’ manufacturing, storing vast intellectual property worth millions.
Real-world breaches underscore the peril: a Waymo engineer stole 14,000 LiDAR files in 2018, and hackers targeted Pfizer-BioNTech vaccine data via the European Medicines Agency in 2020.
Attackers steal KGs to replicate GraphRAG capabilities privately, evading watermarking, which needs output access and encryption, which slows low-latency queries.
Traditional defenses fail in “private-use” scenarios where thieves operate offline. EU AI Act and NIST frameworks stress data resilience, yet no solutions exist for this gap.
AURA’s Adulteration Strategy
AURA shifts from prevention to devaluation: it injects “adulterants”, false triples mimicking real data into critical KG nodes.
Key nodes are selected via Minimum Vertex Cover (MVC), solved adaptively with ILP for small graphs or Malatya heuristic for large ones, ensuring minimal changes cover all edges.
Adulterants blend link prediction models (TransE, RotatE) for structural plausibility and LLMs for semantic coherence. Impact-driven selection uses the Semantic Deviation Score (SDS), Euclidean distance in sentence embeddings, to pick the most disruptive ones per node.
Encrypted AES metadata flags (as “remark” properties) let authorized systems filter them post-retrieval with a secret key, achieving provable IND-CPA security.
Tests on MetaQA, WebQSP, FB15k-237, and HotpotQA with GPT-4o, Gemini-2.5-flash, Qwen-2.5-7B, and Llama2-7B showed 94-96% Harmfulness Score (HS) correct answers flipped wrong and 100% Adulterant Retrieval Rate (ARR).
| Dataset | GPT-4o HS | Fidelity (CDPA) | Latency Increase |
|---|---|---|---|
| MetaQA | 94.7 | 100% | 1.20% |
| WebQSP | 95.0 | 100% | 14.05% |
| FB15k-237 | 94.3 | 100% | 1.50% |
| HotpotQA | 95.6 | 100% | 2.98% |
Adulterants evaded detectors (ODDBALL: 4.1%, Node2Vec: 3.3%) and sanitization (SEKA: 94.5% retained, KGE: 80.2%). Multi-hop reasoning saw rising HS (95.8% at 3-hops), robust across retrievers and advanced frameworks like Microsoft’s GraphRAG.
Ablation studies confirmed the advantages of hybrid generation: LLM-only methods are susceptible to structural checks, whereas link-prediction-only methods are vulnerable to semantic issues.
Even a single adulterant per node was sufficient for over 94% high scores; additional adulterants provided only marginal gains.
Limitations include unaddressed text descriptions on nodes and insider distillation risks, mitigated by API controls. AURA pioneers “active degradation” for KG IP, contrasting offensive poisoning (PoisonedRAG, TKPA) or passive watermarking (RAG-WM).
As GraphRAG proliferates, Microsoft, Google, and Alibaba are investing in this tool, arming enterprises heavily against AI-era data heists.
Disclaimer: HackersRadar reports on cybersecurity threats and incidents for informational and awareness purposes only. We do not engage in hacking activities, data exfiltration, or the hosting or distribution of stolen or leaked information. All content is based on publicly available sources.




")

No Comment! Be the first one.