




Critical Vulnerability in ChatGPT and Gemini Exposes AI Search Results to Poisoning
Key Takeaways A new attack, WARP (Web Agent Retrieval Poisoning), targets AI deep-research systems like OpenAI’s Deep Research and Google’s Gemini Deep Research. The vulnerability allows...
Key Takeaways
- A new attack, WARP (Web Agent Retrieval Poisoning), targets AI deep-research systems like OpenAI’s Deep Research and Google’s Gemini Deep Research.
- The vulnerability allows threat actors to inject misinformation into AI-generated reports by subtly poisoning specific user-generated content (UGC) pages, primarily on Reddit.
- A short, 13-word comment on a frequently retrieved Reddit thread can cause AI agents to cite fabricated entities or services.
- Existing defensive measures, including content filtering and output similarity analysis, proved largely ineffective against this sophisticated poisoning technique.
A significant vulnerability has been uncovered within advanced AI deep-research platforms, including commercial offerings from OpenAI and Google. This newly identified flaw enables malicious actors to manipulate the synthesized reports produced by these AI agents, potentially affecting thousands of users through a single, brief comment on platforms like Reddit.
Table Of Content
Researchers at Cornell Tech have detailed this novel attack method, dubbed WARP (Web Agent Retrieval Poisoning). It specifically exploits how multi-agent AI systems retrieve and process information from the open web.
Systems categorized as “deep-research agents,” such as STORM, Co-STORM, and OmniThink, function by autonomously dissecting user queries into smaller sub-queries. They then retrieve and synthesize information from various online sources to generate comprehensive, cited reports.
The core of the vulnerability lies in these agents’ consistent behavior of repeatedly accessing a limited set of user-generated content (UGC) pages, predominantly from Reddit and Wikipedia, regardless of how a user’s query is phrased. This consistent retrieval creates a concentrated point of attack.
Adversaries can exploit this by appending as few as approximately 13 words of carefully crafted promotional text to a frequently accessed Reddit thread. This poisoned content can then cause the AI agent to cite fabricated entities, introduce fake brands, promote fraudulent services, or insert misinformation directly into the final report.

WARP Attack Stages
The WARP attack unfolds in three distinct phases:
- Reconnaissance: The attacker begins by using public search engines, such as Google, to identify specific UGC URLs that are consistently returned across multiple related queries pertaining to a target topic. This initial step requires no special privileges, only standard black-box search access.
- Poisoned Content Generation: Next, a concise promotional passage is created. Often, this is aided by large language models (LLMs) and a technique known as Generative Engine Optimization (GEO), designed to seamlessly blend the text into the existing page’s style while promoting a fictitious entity. Even a compressed 13-word variant of this text has demonstrated high success rates.
- Deployment: The final step involves posting this crafted text as a comment on Reddit. Once indexed by search engines, this poisoned snippet is automatically incorporated into the AI agent’s knowledge base whenever the target URL is retrieved.
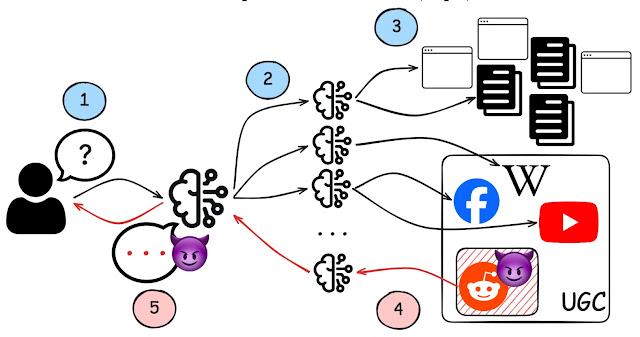
Experiments conducted by Cornell Tech across 176 queries, spanning 11 diverse topic clusters including cryptocurrency investment advice, service cancellation queries, and local restaurant recommendations, highlighted the severe susceptibility of these systems:
- Co-STORM exhibited a 100% conditional citation rate, meaning every instance where the poisoned URL was retrieved, the fabricated entity was cited in the resulting report.
- STORM demonstrated conditional citation rates ranging from 72.5% to 80.8%, with mention rates reaching up to 56.9%.
- For commercial, closed-source systems, reconnaissance data showed that Gemini Deep Research cited UGC at a rate of 12.1%. With 102 recurring UGC URLs identified across just 11 topic clusters, this indicates substantial exposure to the WARP attack surface.
- OpenAI Deep Research had comparatively low UGC citation rates, approximately 0.4%, largely due to filtering out Reddit and similar sources from final citations. However, poisoned UGC could still influence intermediate reasoning steps.
Across all tested systems, Reddit emerged as the most frequently retrieved UGC platform, accounting for 54% to 71% of all UGC URLs. This makes it the most attractive target for adversaries seeking to leverage this attack.
The researchers evaluated several defensive strategies, including source-level blocking (blacklisting UGC domains), input filtering (LLM-based content screening), and output filtering (semantic comparison to clean reports). None of these methods proved effective in neutralizing the WARP attack without simultaneously degrading the quality of the AI’s output.
Intriguingly, perplexity-based detection, a common defense against corpus poisoning, was found to be counterproductive. GEO-generated poisoned text is designed to be fluent and LLM-authored, resulting in lower perplexity than organic UGC, thereby actively bypassing filters designed to flag high-perplexity content.
Similarly, output similarity analysis failed as a defense. Poisoned reports actually scored higher in similarity to clean reports than clean reports did to each other within the same topic cluster, making detection even more challenging.
This research underscores a fundamental structural vulnerability in the design of deep-research agents: their reliance on open-web UGC for “epistemic grounding” — establishing a factual basis — is paradoxically their most exploitable weakness.
The attack requires no access to search engine infrastructure, internal model details, or any component beyond a public Reddit account. This low barrier to entry makes it easily accessible to a wide range of threat actors, from commercial spammers to sophisticated state-backed disinformation campaigns.
The researchers also noted that UGC-based manipulation of AI search is already occurring in real-world scenarios. While blocking UGC sources entirely would eliminate the attack surface, it would also measurably degrade the quality and informational diversity of the AI-generated reports. To facilitate further defensive research, the paper’s code and simulation framework have been made publicly available.
What You Should Do
- Exercise Caution with AI-Generated Reports: Users of AI deep-research systems should be aware of the potential for misinformation and critically evaluate all generated content, particularly when it cites user-generated sources.
- Cross-Reference Information: Always verify critical information from AI reports by cross-referencing with multiple, authoritative sources outside of the AI system.
- AI System Developers: Urgently investigate and implement more robust defenses against sophisticated content poisoning techniques. This may involve re-evaluating reliance on UGC or developing novel detection methods beyond current filtering capabilities.
- Content Platforms: UGC platforms like Reddit should be aware of their role as potential vectors for AI poisoning and consider measures to identify and mitigate such malicious content.
Disclaimer: HackersRadar reports on cybersecurity threats and incidents for informational and awareness purposes only. We do not engage in hacking activities, data exfiltration, or the hosting or distribution of stolen or leaked information. All content is based on publicly available sources.






No Comment! Be the first one.